高速移动下OFDM均衡器的FPGA实现
2 均衡器算法的FPGA实现
当载波数比较大时,OFDM均衡算法所要计算的矩阵比较庞大,计算量大,很难保证实时性的要求。于是人们很自然地会想到用实时性很强的FPGA来实现均衡器的设计,但是均衡本身所需要处理的数据量和运算量都非常大,即使使用FPGA实现也很困难。
若采用文献中的算法运算量是o(N2),假如当载波数N=128时,运算量还是很大的,无法保证实时性。从均衡效果和运算量两方面考虑,采用了文献中的算法。这是一种典型的迭代算法,效果与文献算法相接近,但是在计算中避免了求一个很大的矩阵的逆运算,而是从频域转移矩阵G中提取出了不大的有效矩阵,这样就减少了大量运算。
2.1 硬件设计思想
在对均衡器算法进行FPGA设计之前,先用Matlab仿真该均衡器浮点算法,通过分析程序可以发现,该算法的核心部分是迭代求逆矩阵的过程。该算法的瓶颈主要是求解由复数元素组成的矩阵的逆的计算量巨大,而且是浮点数会占用很大的存储空间。为尽量减少需要使用的逻辑资源,在进行ISE设计时,数据用16位定点数表示,其中高8位是整数部分,低8位是小数部分。
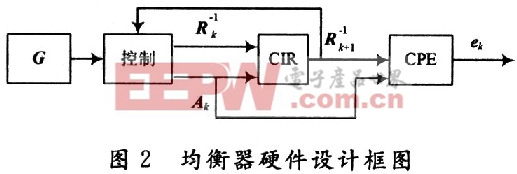
2.1.1 硬件设计框图
实现该均衡器的硬件设计框图如图2所示,其中G为从Matlab中产生的频域转移矩阵,控制模块完成从G中取出对应的有效值得到Ak,并且控制当一组运算完成后运用上一组产生的
2.1.2 CIR模块介绍
CIR模块完成矩阵迭代运算过程,它从输入端口读入Ak以及对应的![]() ,采用迭代的方法计算出
,采用迭代的方法计算出![]() ,用FPGA实现这个模块的端口如图3所示。
,用FPGA实现这个模块的端口如图3所示。
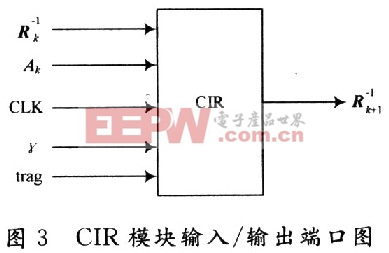
其中,CLK为时钟;γ是模拟信道的信噪比;Ak是频域转移矩阵G中取出的有效矩阵;trag是控制信号,当一次运算结束产生一个有效的![]() 后,只有trag被置为高电平才会进行下一次运算。取Q=2时,
后,只有trag被置为高电平才会进行下一次运算。取Q=2时,![]() 是一个5×5的矩阵。整个求逆矩阵的迭代过程就是从前一个5×5的逆矩阵(即
是一个5×5的矩阵。整个求逆矩阵的迭代过程就是从前一个5×5的逆矩阵(即![]() )和从频域转移矩阵G中对应区域取得的5×9的矩阵Ak运算出下一个5×5逆矩阵(即
)和从频域转移矩阵G中对应区域取得的5×9的矩阵Ak运算出下一个5×5逆矩阵(即![]() )的过程。
)的过程。
分析其矩阵求逆的迭代算法可以发现,其中大部分完成的是复数矩阵的乘加运算,所有数据是复数,虽然复杂很多,但是实际运算中有许多是多余的。Rk是共轭对称矩阵,上三角部分和下三角部分的实部相同,虚部也只是正负相反,所以只需要算出上三角矩阵的数据,下三角的部分直接对虚部取反就可以了。
Xilinx的FPGA芯片中集成了硬核的乘加器DSP48,可以方便、高速地进行乘加运算。但是本算法中涉及到的复数运算比较灵活,还包括一些减法运算,直接使用DSP48不是很方便的控制。故设计了一种乘加器,使用了乘法器的IP Core,按照要求设置输入输出数据位数,其中的一个乘加运算中设置乘法器的两路输入为8位,输出为16位,调用IP Core如下所示,算法中其他的矩阵运算也都与此类似。

a,b作为两个寄存器储存参与运算的数据,outl是乘法器计算的结果,用fcl进行存放,相累加得到f1,再按照共轭复数运算的规律得到nfl。实现一个8位×8位的乘加器共消耗了56个Slice,32个LUT和49个IOB。该乘加器综合后的RTL结构图如图4所示。
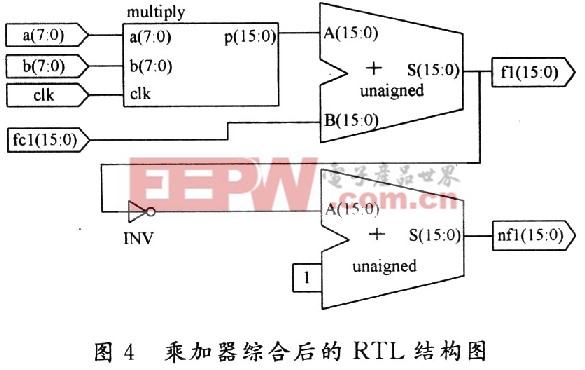
为了能最大限度地提高运算速度,所有数据都用可编程逻辑单元构成的分布式存储器存储并列存储,并且根据算法的要求实现的是多个乘加器同时运算,这样虽然使用了很多逻辑资源,但任何数据都可以即取即用,便于进行大量的并行运算,以提高运算速度。
2.2 系统验证仿真
本系统采用Xilinx公司Virtex-2实验板进行仿真验证,该实验板采用的是XC2VP30芯片,它有30 816个逻辑单元,136个18位乘法器,2 448 KbRAM,资源丰富。开发软件为该公司的集成开发软件平台ISE 9.2,HDL语言采用Verilog,使用Matlab辅助ISE完成FPGA设计的方法。通过实验板上的RS 232串口与PC机进行通信,用Matlab从计算机中传输数据到FPGA芯片中,运算后再通过串口回传均衡后的信号数据到Matlab中仿真验证星座图,以判断该均衡器的效果。







评论