基于FPGA的多时钟片上网络设计
在FPGA 上设计一个高性能、灵活的、面积小的通信体系结构是一项巨大的挑战。大多数基于FPGA的片上网络都是运行在一个单一时钟下。随着FPGA技术的发展,Xilinx公司推出了Virtex-4平台。该平台支持同一时间内32个时钟运行[1],也就是说每个片上网络的内核可以在一个独立的时钟下运行, 从而使每个路由器和IP核都运行在最佳频率上。因此适用于设计多时钟片上网络,实现高性能分组交换片上网络。
本文引用地址:http://www.eepw.com.cn/article/191370.htm1 多时钟片上网络架构的分析
片上网络结构包含了拓扑结构、流量控制、路由、缓冲以及仲裁。选择合适网络架构方面的元素,将对片上网络的性能产生重大影响[2]。
(1)网络拓扑:在设计中,选择Mesh拓扑结构。Mesh结构拥有最小的面积开销以及低功耗的特点。此外,Mesh的线性区的节点数量规模大以及通道较宽。同时,Mesh也能很好地映射到FPGA下的底层路由结构,降低了FPGA 逻辑拥塞和路由器的功耗。
(2)流控机制:虚拟直通和虫洞技术(不像存储转发)有数据包的延时与路径长度成正比。然而,与复杂的虫洞路由器相比, 虚拟直通的路由器更加适合于设计的实现。因此,选择虚拟直通流量控制机制作为路由器的流量控制机制。相比较虫洞机制,它能支持更高的吞吐量,在堵塞时能更有效地释放缓存。此外,虚拟直通流量控制低延时的高信道利用率, 与此同时并不保留物理通道。
(3)路由算法:选择XY算法作为设计所采用的路由算法。该算法中分组的路由只取决于源节点和目的节点的地址,而与网络状况无关。当使用算法时首先在X维上进行路由,当到达与目的节点同一列时,转向在Y维上的路由,最后到达目的节点。该算法对硬件要求简单和实现容易, 在网络流量不大时, 具有较小的时延,能够有效避免死锁和活锁。
(4)仲裁机制:输入端口分配是基于简单的Roundrobin[3]机制。上次接收或解决接收的端口会放在队列的末端。切换时到下游的数据包。当交换数据包时,FIFO的虚拟通道也遵循这种机制。
2 路由器微节点结构的设计
多时钟片上网络的路由器由5个输入端口、交叉点矩阵和中央的仲裁器三部分组成。除了头译码逻辑,5个输入端口都是相同的。由于设计中采取了虚拟通道流控机制(VCS),因此输入端口就必须包含仲裁逻辑。与此同时, 输入端口还应包含输入缓冲区来存储输入的数据包。
2.1 数据包
利用Xilinx block RAM, 设置深度为16的FIFO(先入先出队列),数据包的大小能在24 位与128 位之间变化,每个数据包header(包头)占用一个flit(数据片)。flit 的大小固定在8位。数据包头包含路由目标地址、flit的类型以及部分数据包。设计中采用的虚拟直通流量控制需要1 位去指定数据片的类型。路由器支持可变化大小的数据包, 通过编码将数据包的大小编译为字段,作为bRAM所需要的部分,放在数据包头部。每个IP核的网络接口(NI)起到存储在数据包头部的信息的作用。当需要更高粒度数据包时,部分数据包的位数以及宽度将会相应的增加。增加部分数据包的位数的同时也提高了缓存的利用率。数据包首部保留的位数将用于实现基于优先级的流量控制。
2.2 输入端口
路由器有5个输入端口, 通过端口分别与内核及邻近的路由器通信, 这5个端口按在方位可分为本地(L),北(N),东(E),南(S),西(W)。每个输入端口可以支持虚拟通道多路复用,相关联的仲裁器,以及头译码逻辑,从而作出路由决定。如图1,输入端口的3 个主要组成部分分别是虚拟通道选择器、FIFO bRAMs以及bRAM仲裁器。虚拟通道选择器:决定输入端缓存的使用空间的决定权在虚拟通道选择器。当数据包大小以编码形式传播时,虚拟通道选择器接收数据包的首部。当虚拟通道选择器收到来自上游路由器或者来自自身核心的数据时, 虚拟通道选择器就会拿数据包的大小跟虚拟通道目前可以容纳数据包的大小进行比较。
这么做的目的是为了能够使输入的数据能够符合FIFO 中write_count的大小。如果有足够的空间存在,则虚拟通道选择器将同意输入请求, 同时反馈信息。在此过程中,虚拟通道选择器还设置了输入端解复用器。解复用器的作用是使数据包从输入通道传输到正确的复用器的输入缓存中。FIFO bRAMs:在所设计的路由器中,缓冲区的深度将参数化,在试验时同时将其深度设置为16 。这些缓存区将被作为bRAM FIFO的存储器,同时起到以下作用:
(1)缓冲部分或者全部到来的数据包,以及当下游开关可以用时,传送头部及紧跟的flit。
(2)划分路由器核心以及路由器的频率,从而支持一个多时钟的网络设计。
(3)通过仲裁器监察write_count 端口的信息,来实现支持可变化大小的数据包。在缓冲区有单独时钟域的情况时, 就需要一种有效的方式实施完整的或者空的逻辑。通过以下方式使控制信号同步:
(1)发送数据包粒度作为一小部分FIFO 的空间。
(2) 在一个时钟周期内, 一个连接终止之前设置flit的尾部位。在所使用的FPGA 设计中,由于支持FIFO的最小深度是16, 所以它适合于在虚拟直通中缓冲整个数据包。write_count的空和满状态信号将集成在FIFO中。在一个多数据包的缓冲区中加大存储flit的能力,将有助于提高FIFO的利用率。此外,获得网络的吞吐量的增益,是由于上游连续包释放缓冲区所促成的。
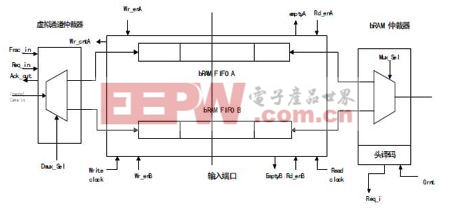
图1 输入端口设计图
bRAM仲裁器: 输入端口还包含了控制逻辑作出的仲裁决定。当选择一个非空的bRAM时, 简单的Round-robin的方式仲裁算法将会启用。当选择bRAM时,FSM将会送出头部flit,解码出它的目的地址,并发送相应的要求。在所设计的路由器中采用XY路由算法将大大简化了解码器的逻辑结构。根据XY路由算法的通行路径许可,即将释放的请求线将会减少。
头译码器:在XY路由算法中,头数据片一开始往X轴方向走,当到达X轴所在的目标地址时,就会往Y方向走。所有紧随着的数据片将以流水线的方式跟着头数据片移动。这种简便的XY路由算法适用于减化头解码器、交叉点矩阵以及中央仲裁器的逻辑结构。以上简化得逻辑结构将使FPGA的芯片数显著减少。
2.3 交叉点矩阵
设计一个多路交叉点矩阵, 目的是为了减少面积的使用。而另一种设计是支持复分解虚拟通道的交叉点连接。后一种方法,产生高网络吞吐量,但要增加一个重要的复杂性开关。交叉点支持并行连接,以及被用于通过中央仲裁器支持多个信号同时请求。并非所有的交叉点连接都是使用XY 路由算法。经过逻辑优化,如图2所示设计中实施简单的4 和2 输入多路复用器开关(分别是L、N、S、E 以及W 端口)。上述优化方案减少了交叉点面积,使其使用的切片只有32 片。因此,达到路由器面积显著减小的目的。

图2 交叉点矩阵
输入端口的分配方式将采用简单的Round-robin仲裁机制。对上一次接收过的或没有用到的端口将给予最低优先级,并排在队列的最末端。将通过以下的方式提高路由器的性能:
(1)降低中央仲裁器的逻辑复杂度;
(2)尽量集中仲裁器,以减少req/grant 信号的数量。
在设计中减少逻辑复杂度以及布线, 从而减少数据堵塞,达到提高性能以及减低功耗的效果。
3 性能分析
利用Virtex-4系列中XC4VLX100-11[4]设备进行设计, 利用Xilinx ISE 8.2i 进行综合布局布线。使用ModelSim 6.1c[5]验证所设计的功能。设置了单一时钟和多时钟进行了模拟,分析多时钟片上网络的性能。由于路由器是直接连接到内核, 所以没必要考虑片与片之间的延时而去估计最高的频率。所设计是由一个路由功能模块(RFM)执行[6],用以准确地估计工作频率,基本路由器的单机版工作频率可到达357MHz。因此8bits 通道的路由器的吞吐量最高可达2.85Gbits/s。在所设计的路由器中, 头数据片前进到下一个节点,而剩下的数据片以流水线方式流通。在计划中,网络延时仅仅与路径长度H(跳跃点数量)有关。在信道争用的情况下,网络延时L 可以用以下方式计算:
L = 7×H + B/w (1)
公式(1)中,B是数据包的字节数,w是每个时钟周期转换的字节数。参数7是在多时钟片上网络路由器中安装在每个路由器跳延迟支付。这个延时是因为基于数据包中的头数据片的解码和仲裁执行所导致的。
为了评估所设计的多时钟架构的性能, 将利用所设计的路由器的VHDL模型,模拟一个3×3Mesh结构,在本身频率下执行包装产生的数据包。路由器的频率值会在拓扑结构合成,布局和布线阶段完成之后得出。对于不同的配置(资源的可用性、跨路由器的距离、bRAM/dRAM FIFO 的版本),路由器的频率可以降低高达18%[6]。图3显示了单一时钟与多时钟,在延时与注射速率关系中的曲线图。在单一时钟时,网络的频率为286MHz。而在多时钟时, 频率的范围是从286MHz~357MHz。图3中,X轴表示的注射率是在一个周期内每个节点注入flit 的数量。Y轴曲线测量的是每个实例中数据包的平均延时。可以看出,所提出的多时钟片上网络相比单一时钟片上网络的性能显着增加。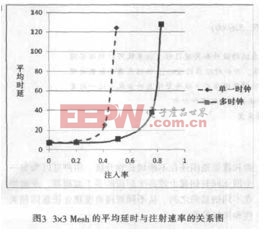
4 结语
本文介绍了一个基于FPGA 的高效率多时钟的虚拟直通路由器,通过优化中央仲裁器和交叉点矩阵,以争取较小面积和更高的性能。同时,扩展路由器运作在独立频率的多时钟NoC 架构中,并在一个3×3Mesh 的架构下实验,分析其性能特点,比较得出多时钟片上网络具有更高的性能。












评论