常用数据无损压缩算法分析
当今,各种信息系统的数据量越来越大,如何更快、更多、更好地传输与存储数据成为数据信息处理的首要问题,而数据压缩技术则是解决这一问题的重要方法。事实上,从压缩软件WINRAR到熟知的MP3,数据压缩技术早已应用于各个领域。
2 数据压缩技术概述
本质上压缩数据是因为数据自身具有冗余性。数据压缩是利用各种算法将数据冗余压缩到最小,并尽可能地减少失真,从而提高传输效率和节约存储空间。
数据压缩技术一般分为有损压缩和无损压缩。无损压缩是指重构压缩数据(还原,解压缩),而重构数据与原来数据完全相同。该方法用于那些要求重构信号与原始信号完全一致的场合,如文本数据、程序和特殊应用场合的图像数据(如指纹图像、医学图像等)的压缩。这类算法压缩率较低,一般为1/2~1/5。典型的无损压缩算法有:Shanno-Fano编码、Huffman(哈夫曼)编码、算术编码、游程编码、LZW编码等。而有损压缩是重构使用压缩后的数据,其重构数据与原来数据有所不同,但不影响原始资料表达信息,而压缩率则要大得多。有损压缩广泛应用于语音、图像和视频的数据压缩。常用的有损压缩算法有PCM(脉冲编码调制)、预测编码、变换编码(离散余弦变换、小波变换等)、插值和外推(空域亚采样、时域亚采样、自适应)等。新一代的数据压缩算法大多采用有损压缩,例如矢量量化、子带编码、基于模型的压缩、分形压缩和小波压缩等。
3 常用数据无损压缩算法
3.1 游程编码
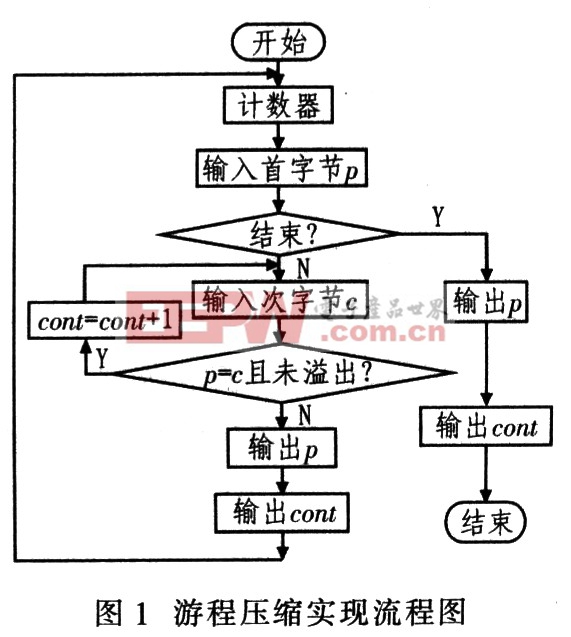
这种数据压缩思想:如果数据项d在输入流中连续出现n次,则以单个字符对nd来替换连续出现n次的数据项,这n个连续出现的数据项叫游程n,这种数据压缩方法称游程编码(RLE),其实现流程如图1所示。RLE算法具有实现简单,压缩还原速度快等优点,只需扫描一次原始数据即可完成数据压缩。其缺点是呆板,适应性差,不同的文件格式的压缩率波动大,平均压缩率低。实践表明,RLE能够压缩复杂度不高的原始点阵图像。
3.2 基于字典编码技术的LZW算法
LZW算法是LZ78的流行变形,由Terrv Welch在1984年开发。LZW算法首先将字母表中的所有字符初始化到字典,常用8位字符,在输入任何数据前优先占用字典的前256项(0~255)。LZW编码的原理:编码器逐个输入字符并累积一个字符串I。每输入一个字符则串接在I后面,然后在字典中查找I;只要找到I,该过程继续执行搜索。直到在某一点,添加下一个字符x导致搜索失败,这意味着字符串I在字典中,而Ix(字符x串接在I后)却不在。此时编码器输出指向字符串,的字典指针;并在下一个可用的字典词条中存储字符串Ix;把字符串I预置为x。其压缩流程如图2所示。
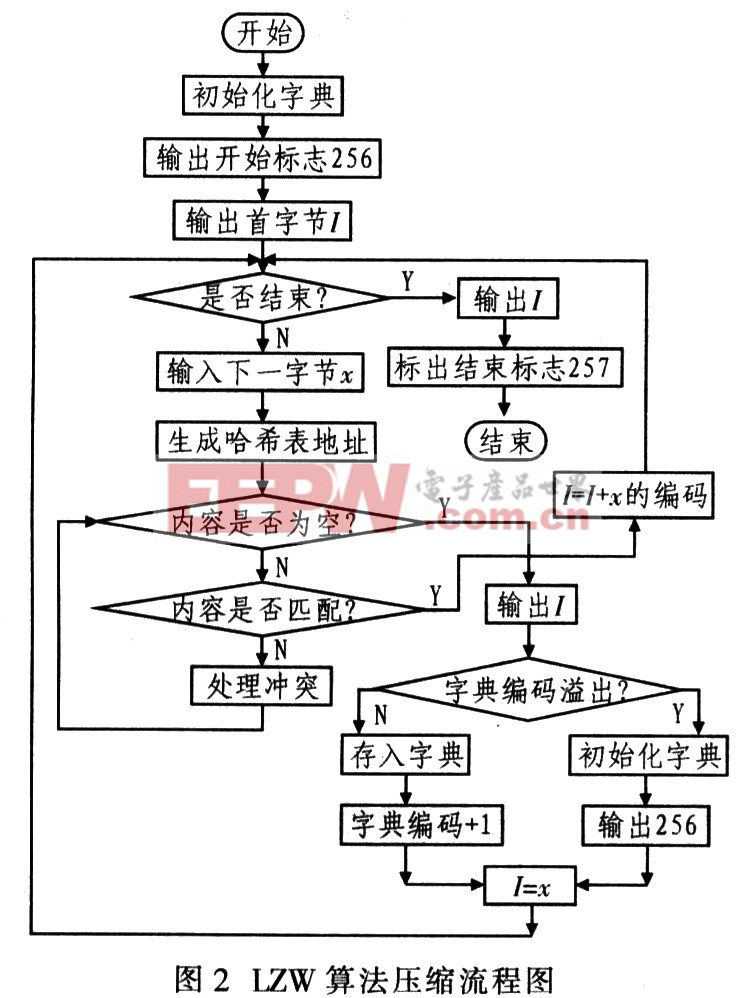
因为字典的前256项被占用,因此字典指针必须高于8位。由于LZW算法的字典中的字符串每次仅增加一个字符。因此,要获得长字符串则需较长时间,这样才能较好地压缩.IZW编码能够适应输入数据。
LZW算法与其他算法相比具有自适应的特点,即可以根据压缩内容不同来建立不同字典,以减少冗余度,提高压缩比;并且解压时这个字典无需与压缩代码同时传送,而是在解压过程中逐步建立与压缩时完全相同的字典,从而完整、准确地恢复被压缩内容。因此,LZW算法是一种解码速度与压缩性能较好的压缩算法。
实现LZW算法需要考虑以下几点:
(1)字典建立(数据结构与字典大小) LZW字典的数据结构是一棵多叉树。字典越大,代替的子串越多。但应用中字典容量则受一定限制,要权衡利弊选择合适的字典。





评论