基于ARM7TDMI内核SEP3203处理器的语音信号的软件实时编解码的实现
根据语音实时性的需要,设置UCB1400采样速率为8 kb/s。该芯片用16位表示一个采样点,故采样速率为128 kb/s。编码后,每个采样点用4位表示,故传输率为32 kb/s。
3.2 软件系统
软件流程如图4所示。每帧数据为64个采样点,共计为128字节、16位表示的PCM码,编码后为32字节、4位表示的ADPCM码。
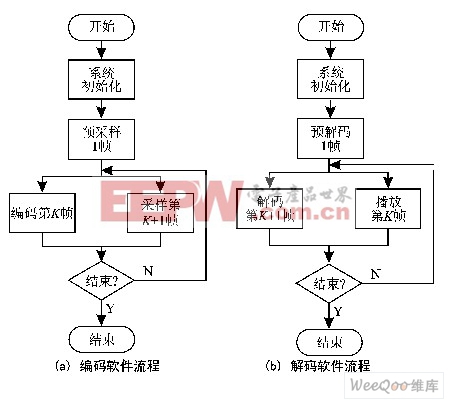
图4 编解码的软件流程
(1) 编码
首先对系统初始化,包括对AC97、CODEC、DMAC等模块配置,以及有关状态变量的初始化。然后,采样第1帧语音数据,采样结束进入DMA中断,在中断处理中再次配置DMAC,触发新的采样传输,并对刚采样的数据编码。由于编码由内核执行,采样由CODEC和DMA完成,故对第K帧编码和对第K+1帧采样是并发进行的。
(2) 解码
同编码过程类似,首先对系统进行初始化,然后解码第1帧音频数据。解码完配置DMAC,触发数据传送至AC97输出FIFO,通过放音设备播放录音。同样,解码第K+1帧数据与播放第K帧数据并发进行。
本设计采用“双Buffer”机制缓冲数据。“双Buffer”是指:开辟两个帧缓冲区为Buf0、Buf1,缓冲标志Flg初始为0。编码时,采样第1帧数据,DMA从AC97输入FIFO向Buf0传输数据,传 输完后,设置Flg=1,编码器从Buf0中取数据编码;同时,DMA向Buf1中传送新数据。周而复始,每帧数据采样完,设置Flg=!Flg,编码器从Buf!Flg缓冲区取数据编码,DMA传送采样数据的目的地址为Buf Flg,从而实现了第K+1帧数据采样和第K帧数据编码并发。只要编码速度高于采样速度,就不会出现数据的覆盖。处理过程如下(解码时的情况类似):

4 性能优化
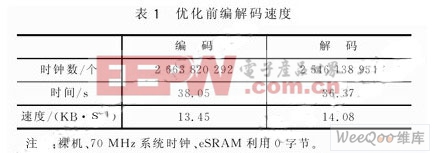
语音处理的实时性要求很高,否则,若数据处理速度跟不上语音变化速度,就会在录音时出现刚采样的数据覆盖了先采入但未处理的数据;在放音时,出现播放的速度比实际语音慢。当然,如果用足够大的缓冲,可以避免录音出现的问题,但放音出现的问题是无法避免的。同时,鉴于存储资源对于嵌入式系统是很宝贵的,故此方案没有实际价值。上文介绍的“双Buffer”机制,能够使采样和编码之间、解码和播放之间分别互不影响、并发执行,易于控制;但要满足实时性要求,还要使编解码速度符合采样和播放的要求。语音速率是8 KB/s,而系统中一个采样点用16位表示,故编解码速度不能低于16 KB/s(即每秒至少编码16 KB的PCM码,每秒至少解出16 KB的PCM码)。表1是未对系统优化前,测试裸机无操作系统情况下,处理512 KB的PCM码(对应128 KB的ADPCM码)所用时间。该测试是使用SoC内部定时器TIMER进行的,见参考文献。测试结果显示,系统优化前没有满足语音实时性要求。
到此,系统目标代码都是在SDRAM中运行的。SEP3203提供了一个很有用的模块——片内高速存储器eSRAM。eSRAM存取速度非常快,可达到0.89 MIPS/MHz,所以对系统性能有很大的优化作用,而SDRAM却只能有其性能的1/3左右。表2是在50 MHz时钟、32位ARM指令情况下,SDRAM和eSRAM的性能比较。各项指标的意义见参考文献。



评论