一种基于信息熵的WSN节点拥塞避免机制
1.2 WSN中信息熵的数学定义
在此基于WSN的网络模型和信息论,给出WSN节点的信息熵的数学定义。
定义1:节点信息熵:根据香农的定义,自信息的数学期望为信息熵,因此节点信息熵表示节点N每发送一个数据包所提供的平均信息量:

式中:q表示ai(i=1,2,…,q-1,q)的取值有q种可能性;P(ai)为字符ai出现的概率,节点信息熵H(X)表征了传感器节点整体的统计特征,是总体平均不确定性的量度(单位:比特/数据包)。式(1)中的单位取决于对数函数的底数。本文中,取对数函数底数为2,即表示每个数据包含有1比特的信息量。
在无线传感器网络中,节点感知到的数据既存在一定的差异又有一定的冗余,为了表征节点之间的这种关系,下面引入了节点相对信息熵。
定义2:节点相对信息熵:假设P和Q是两个概率分布函数,则定义P相对于Q的信息距离即节点相对信息熵为:

式中:Pi和Qi为一个字符在节点中所出现的概率。
节点相对信息熵可用于计算任意两节点之间节点信息熵的差异性的大小。它的物理意义是两组概率分布之间的差异性程度,因而对于两组不同的概率分布P和Q,计算其节点相对信息熵D(P‖Q),如果这个值越小,表明两组概率分布越接近,这两个节点之间的数据相似程度越大,则节点P就可以减少向节点Q发送数据包以保证网络的畅通。对于极限情况,当D(P‖Q)=0时,表示两组概率分布完全相等,则这两个节点之间的数据几乎一样,此时,节点P可以暂停向节点Q发送数据包。
1.3 基于节点信息熵的拥塞避免策略
在一种路由协议机制下,若一个数据包从节点u发送至邻居节点d,则称u是d的上游节点,d是u的下游节点。在本文的网络模型中,总是假设路由机制是静态的或是很少进行更新的,因此可知每个下游节点d总是可以知道有多少个上游节点u。按照上述基本假设,本文提出的拥塞避免策略过程如图2所示。本文引用地址:http://www.eepw.com.cn/article/161901.htm
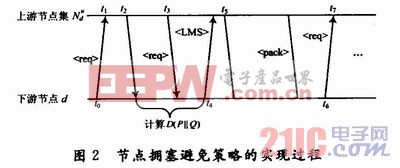
1.4 算法的分析与实现
在这里以双重身份节点m(节点m既可以看作下游节点,也可以看作上游节点)作为主要考虑节点,首先当节点m作为上游节点时,向其自己的上游节点发送消息req>,然后根据上游节点集反馈回来的消息req>来计算节点相对信息熵的大小,根据计算出来的节点相对信息熵的大小来决定其分配的发送数据窗的大小。其中消息req>主要包含发送节点的id、各数据包的信息量大小以及统计特性等信息。具体的拥塞避免算法实现过程如下:
(1)如果节点m发送数据窗SDWm>0且当前信道可用,则节点m根据其收到的下游节点发送的广播消息LMS>来决定发送自己的数据窗大小;
(2)否则节点m发送数据窗SDWm=0,然后向其上游节点集发送消息req>;
(3)如果仅作为上游节点u的发送数据窗SDWm>0,则上游节点u退出上游节点集![]() ,此时上游节点u不响应下游节点d发送的req>,也不发送消息req>;
,此时上游节点u不响应下游节点d发送的req>,也不发送消息req>;
(4)如果仅作为上游节点u发送数据窗SDWm=0,上游节点集![]() 则向下游节点发送消息(req>;
则向下游节点发送消息(req>;
(5)下游节点m收到消息req>开始计算节点相对信息熵的大小;
(6)根据计算得到节点相对信息熵的大小向上游节点集![]() 广播消息LMS>,通知上游节点u各自发送数据窗的大小,然后上游节点u根据收到的发送数据窗的大小来决定向下游节点发送一定数量的数据包,其中广播消息LMS>主要包括发送节点id及相应发送数据窗的大小,且各发送数据包的大小之和小于本地可用缓冲区间。
广播消息LMS>,通知上游节点u各自发送数据窗的大小,然后上游节点u根据收到的发送数据窗的大小来决定向下游节点发送一定数量的数据包,其中广播消息LMS>主要包括发送节点id及相应发送数据窗的大小,且各发送数据包的大小之和小于本地可用缓冲区间。
在上述过程中,若上游节点u当前的发生数据窗大于0,则不响应下游节点d发送的req>,也不发送消息req>,此时下游节点d不为上游节点u重新分配发送数据窗;若上游节点u完成了当前的发生数据窗,则等待下游节点d发送下一个消息req>。因此每个上游节点只有在收到消息LMS>和之后的req>之间发送数据包,可得知下游节点d处不会产生数据拥塞,整个网络的节点拥塞因此而避免发生。
2 实验仿真
为了验证本文所提出的避免节点拥塞机制的性能,选取经典的CODA算法作比较。现假设本文的仿真实验环境设置如下:
(1)选取200个节点随机部署在600×600的正方形区域内,基站选择在该区域边界上;
(2)节点的位置是固定的,且节点之间的通信半径R=50,网络带宽设置为1 Mb/s;
(3)信道质量相对可靠,可忽略信道对误码率的影响,源节点产生的数据包大小相同,且报文的产生率为每单位时间10个数据包,节点可用最大缓冲区间为15个数据包。









评论