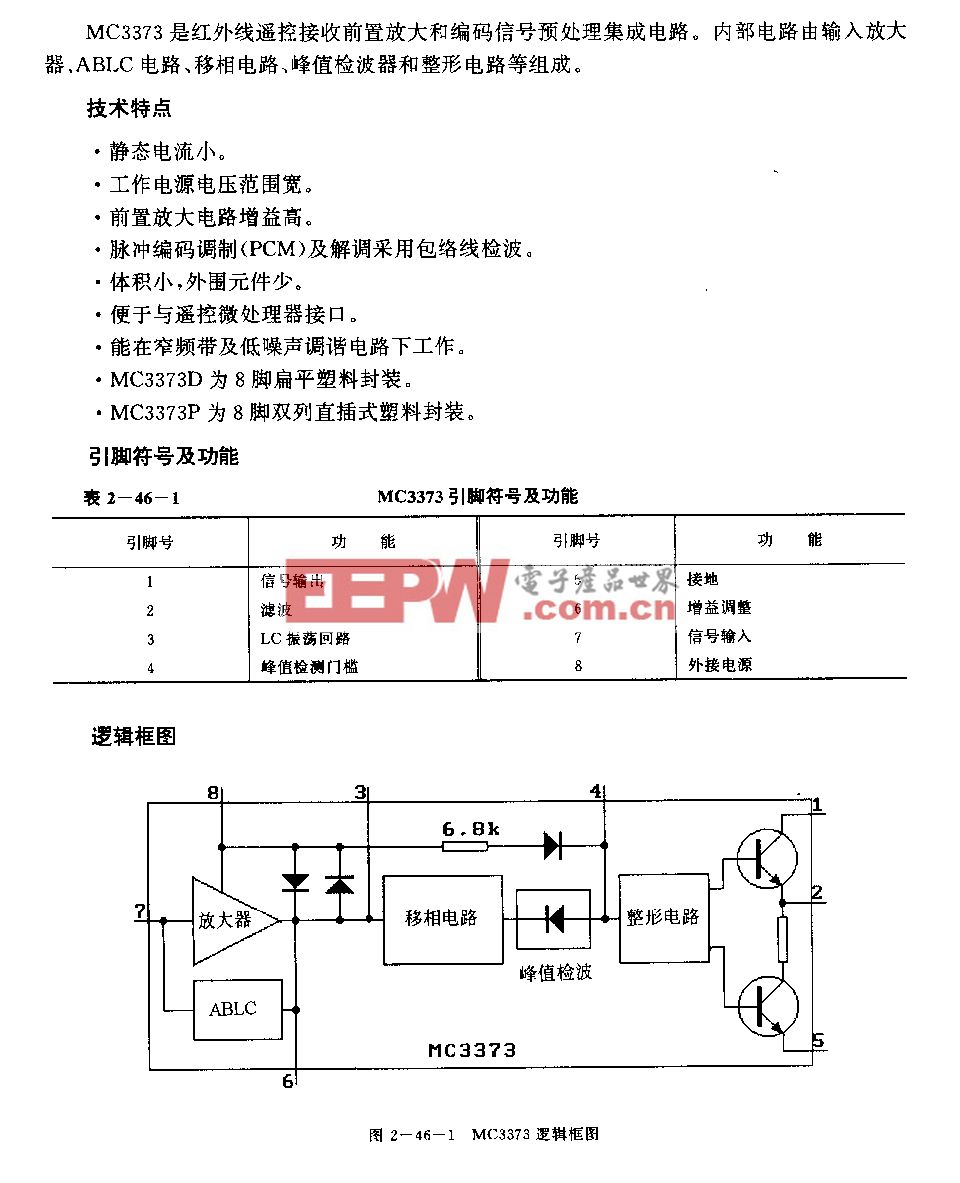
FPGA 协处理的进展
尽管FPGA架构具有许多出众的性能,一些性能必须共同发挥作用,才能提供优于CPU协处理的解决方案。
芯片与算法基础
大部分双精度浮点算法的加法与乘法操作比例大约为1:1。在FPGA中,加法运算使用逻辑资源,乘法运算使用DSP块,因此FPGA的逻辑资源与DSP块的比例必须均衡。FPGA的另一个特点是其可编程功率技术,该技术可针对所有逻辑块、DSP块与存储器块进行编程,根据设计的时序要求将其设定为高功耗或低功耗模式。
浮点运算核已经改进,可运行于更高的时钟速率,使用更少的DSP块和更少的逻辑资源。采用浮点编译器可减少不同浮点运算核之间用于连接64位数据通路的逻辑资源。
在一次浮点运算结束时,合并对浮点运算进行规格化处理(定点格式转换至浮点格式)的步骤,可以显著减少对后续浮点运算输入的去规格化处理(浮点格式转换为定点格式)。浮点运算的数学表达式的整个数据通路可熔接在一起,这会最多减少40%的逻辑资源并使时钟速率略有提高。
浮点运算的正确组合十分重要。如果算法有许多超越运算(求指数、求对数等),FPGA可配置所需要的数目。在GPGPU设计中,会增加一些硬模块实现上述函数,但比例比单精度浮点逻辑少得多。使用算法技巧、抽象硬件细节及针对个别FPGA资源的优化都需要函数库。
基于芯片、算法与库基础,图2的系统级解决方案涉及到了工具链、模块/板级设计、CPU接口以及采用合作公司专门技术的由CPU至基于FPGA的加速器的数据传输。
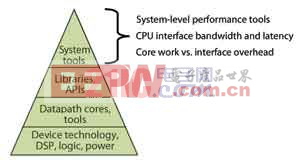
图2 FPGA加速系统级解决方案的基础
使持续性能接近峰值
对于可并行化或流水化的任务,相对于峰值性能而言,FPGA经常能够大大提高持续性能,并可利用各器件资源。以一个蒙特卡洛布莱克-斯科尔斯基准测试程序为例,它可建立一条运行频率为150MHz的等式流水线。
在每个时钟周期,FPGA通过梅森素数旋转核产生的随机数被输入(接入)“定制指令”,每个时钟周期产生一个结果。12条“定制指令”与模块的两片FPGA匹配,利用双精度浮点逻辑输出12×150M=1.8G结果/秒。通过额外倍频,可预期实现性能为上述性能的两倍。
对比不同架构的浮点能力持续性能与峰值性能十分有趣。表2给出了四种可能解决方案的单精度浮点峰值性能。由于布莱克-斯科尔斯公式需要常规加法与乘法函数以外更多的函数(指数、平方根等),布莱克-斯科尔斯结果的总GFLOPS未作统计。
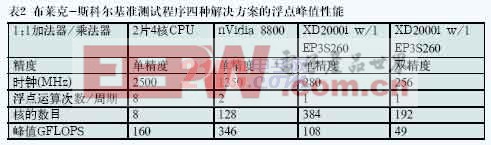
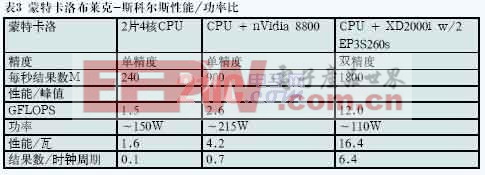
表3给出了布莱克-斯科尔斯结果与峰值GFLOPS的比例,作为比较持续性能与峰值性能的一种相对衡量方法。相比峰值性能,FPGA达到了最佳持续性能。相比另外两种加速器的单精度逻辑,FPGA的双精度逻辑具有最优原始性能以及最优的“性能/瓦”参数。
对许多包含并行性或可流水化的算法而言,由于裕量连接带宽可实现用户自定义的数据通路,这样,逻辑可在一个时钟周期内访问存储器或访问另一个逻辑块的结果,从而使FPGA的持续性能可接近峰值性能。由于固定架构具备预先确定的用以实现不同功能的逻辑块集合,所以可以为FPGA配置支持某种给定算法的最优逻辑函数比例来实现器件资源的最佳利用。









评论