基于改进平衡Winnow算法的短信过滤系统
2 构造分类器
训练分类器是研究的重点,采用Balanced Winnow 算法并对其进行改进。
2.1 Winnow 分类算法
Winnow 算法是二值属性数据集上的线性分类算法。线性分类问题中表示分类界限的超平面等式如下:
w0α0+w1α1+w2α2+…+wkαk=0 , 其中:α0,α1,…,αk分别是属性的值;w0,w1, …,wk是超平面的权值。如果其值大于0 , 则预测为第一类否则为第二类。
Winnow 算法是错误驱动型的分类算法, 即当出现错分的实例时才更新权值向量。设定两个学习系数α 和β(其中α>1,β<1) , 通过将权值乘以参数α( 或β) 来分别修改权值。
2.2 Balanced Winnow 分类算法
标准的Winnow 算法不允许有负的权值, 于是就有了另一个称为平衡的Winnow 版本, 允许使用负的权值。
对Winnow 算法的基本形式, 权重向量的每一维都是正数。Balanced Winnow 是用w+-w-代替w, 当
 则将实例归为该类。Balanced Winnow 的权重更新策略为:
则将实例归为该类。Balanced Winnow 的权重更新策略为:(1) 如果
 , 但文本不属于该类, 则要降低权重: 对j=1,,…,d,如果xj≠0 , 则xj≠0 , w+j =βw+j ,w-j =αw-j ,α>1,0<β<1。
, 但文本不属于该类, 则要降低权重: 对j=1,,…,d,如果xj≠0 , 则xj≠0 , w+j =βw+j ,w-j =αw-j ,α>1,0<β<1。(2) 如果
 但文本应属于该类, 则要提高权重: 对j=1,2,…,d,如果xj≠0, 则w+j =αw+j ,w-j =βw-j ,α>1,0<β<1。
但文本应属于该类, 则要提高权重: 对j=1,2,…,d,如果xj≠0, 则w+j =αw+j ,w-j =βw-j ,α>1,0<β<1。在实验中, 采用文献[7] 中统一α 和β 为一个参数的方法, 令β=1/α, 没有影响分类效果, 但有效简化了参数的选择。可以为不同的类别确定不同的θ 值, 但实验表明: 对于不同的类别选择同样的θ 值, 结果几乎是一样的, 所以在每次独立的实验中都取相同的θ 值, 大小是训练文本所含的平均特征数, 而初始的w+和w-分别取全2 和全1 向量。
在平衡Winnow 算法中, 一旦参数α、β 和阈值θ 确定下来后, 将在训练过程中不断更新权重向量w+和w-至最适合这组参数。因此对参数的依赖较小, 需要手工调整的参数不多。
2.3 去除野点
在短信过滤中,短信样本是由手动或自动方式收集的, 收集的过程中难免会出错, 因此短信样本集中可能存在一些被人为错分的样本点, 即野点。这些野点在训练时, 会使得分类器产生严重的抖动现象, 降低分类器的性能。因此,好的分类器应具有识别野点的能力。
对于Winnow 算法,若样本中存在野点, 则野点在训练时以较大的概率出现在两分类线之外, 且分类错误。
这些野点对分类器的训练过程产生很大的影响, 可能会造成分类器的“ 过度学习” 。因此引入损失函数, 按照损失函数的定义, 这些野点损失较大, 因此可以通过给损失函数设置一个上界函数来处理线性分类器中的野点问题, 如图1 所示。
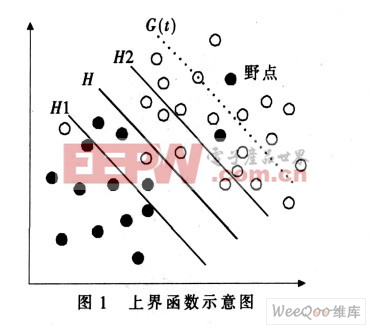
图1 所示为两类线性可分情况, 图中实心点和空心点分别表示两类训练样本,H 为两类样本没有被错误地分开的分类线,H1 和H2 分别为平行于分类线H 且与分类线H 的距离为单位距离的两条直线。直线G(t)为平衡Winnow 算法中第t 轮迭代后损失函数的上界线。该上界线是关于迭代次数t 的函数, 因此可以将该上界线G(t)对应的上界函数记为g(t)。从图1 可知, 在直线G(t)左下侧误分样本的损失较少, 可以认为这些误分样本是由于当前分类器的性能较低而误分的; 在直线G(t) 右上侧误分的样本由于在第t 轮迭代后损失仍较大, 则可以认为这些误分的样本是野点。根据线性分类器和野点的性质可知,上界函数g(t)具有以下性质:
(1) 随着Winnow 算法中迭代次数t 的增加, 上界函数g(t) 单调递减, 并且递减的速率也随着t 的增加而递减, 即上界函数的导数g(t)为单调递减函数;(2) 上界函数既不能太大, 也不能太小。太大会降低判断野点的能力, 太小则会误判正常样本为野点。
根据上界函数的这些特性, 可以考虑一个平行于分类线H 的线性函数作为损失函数的上界函数。即g(t)=
 其中:ε 为常数值; 直线G(t) 平行于分类线H;η 为损失因子, 也称为学习率, 可以在训练分类器的时候指定其值。
其中:ε 为常数值; 直线G(t) 平行于分类线H;η 为损失因子, 也称为学习率, 可以在训练分类器的时候指定其值。在每一轮训练中, 若该样本的G(t) 值大于分类线的值, 并且超过一定的阈值, 且不属于该类, 则判定该样本具有野点的性质, 应当在训练集中将该样本去除, 以便提高下一轮训练的准确性。这样不仅有效削弱了分类器的抖动现象, 而且提高了分类器的性能。








评论