改进遗传算法的支持向量机特征选择解决方案介绍
交叉操作的作用是通过交换两个染色体之间的若干位从而生成含有部分原始优良基因的新个体。由式(3)可知互敏感度信息量可作为不同特征之间含有相似分类信息的一种度量,所以可以将互敏感度信息量代入式(4)计算出染色体在第位发生交叉的几率b(i),在式(4)中i和j分别代表特征i和特征j,是染色体的长度。b(i)是特征i相对于其他所有特征在互敏感度信息量上的归一量,反映了特征与其余特征在相似信息量上的总和。由此对应到染色体上,b(i)就可以认为是染色体的第i位与整个染色体在基因信息上的相关性,b(i)越小则说明相关性越大,第i位与整个染色体所含的基因信息越接近,此位为分裂点的几率越小。由于b(i)是归一化量,故可采用轮盘算法来选择一个交叉点。

变异操作是引入新物种的重要手段,可以有效地增加种群个体的多样性。本文中的变异率Pm采用相邻两代之间的最优适应度增幅比作为自变量进行自适应调节,如式(5)所示。当适应度增幅比正向增大时,较小的增幅比可以使变异率维持在中等水平,并且变异率随着增幅比的增大而缓慢降低,这样既能够拥有一定数量的新个体也可以抑制过多不良染色体的产生,保证优秀染色体的进化足够稳定;而当适应度增幅比反向增大时,由较小增幅比则可以获得较高的变异率,并且变异率也伴随增幅比同比缓慢升高,确保有足够的染色体发生变异,稳定地加快进化速度。
式中dis指新生种群的最优适应度相对于原种群的最优适应度的增幅比,j与k均是区间(0,1)上的调节系数。文中的j与k分别取0.65和0.055。
独立敏感度信息量在一定程度上体现了单个特征所含有的分类信息量,如果独立敏感度信息量小,则说明该特征所含信息大部分对分类没有帮助,即该基因位发生突变后对整个染色体的优异性影响不大,突变的概率也就相应减小。因此将独立敏感度信息量归一化后所得到的q(i)作为特征i被选为变异点的概率。变异点的具体选择方法为:针对一个染色体按照染色体的位数进行循环遍历,在该循环中由变异率Pm判定是否产生变异位。若需要产生变异位,则依据q(i)按照轮盘算法进行选择。
模拟退火选群
在每一轮进化完成后都需要决定进入下一轮进化的种群。如果过多地将较优种群作为父代,就会使算法过早收敛或搜索缓慢。文献[7]中指出模拟退火算法能够以一定的概率接受劣解从而跳出局部极值区域并最终趋于全局最优解,因此可以将上文提到的最优适应度增幅比作为能量函数,运用模拟退火的Meteopolis准则来选择待进化的种群。为了使每个种群得到充分地进化,预防最优解的丢失,这里采用设置退火步长的策略来实现模拟退火选群。该策略具体为:使退火步长对同一种群作为父代的次数进行计数,一旦产生更优种群则退火步长就置零并重新计数。若退火步长累计超过一定的阈值时,就进入模拟退火选群阶段。退火步长累计到一定数量意味着原有种群的进化已经停滞,需要用模拟退火算法摆脱这种停滞状态。如果增幅比大于零,则说明新生种群优于原有种群,这时完全接受新种群进入下一轮进化;否则新生种群劣于原有种群,并以一定的概率p接受较劣的新生种群[8]进入下一轮进化。接受概率p由式(6)和式(7)共同决定,其中dis为增幅比,T(s)指温度参数,T0和s分别是初始温度和迭代次数。

以上两式的参数要满足进化对接受概率的要求。即增幅比负增长越大,接受概率降低越迅速,但接受概率随迭代次数的增加应缓慢下降。这样做能够保证在有限的迭代次数内有一个适应度较优的新生种群进入下一轮进化,以达到减少计算量和优选待进化种群的目的。在本文中T0=0.2,A=0.9,m=0.5。
实例的验证与分析
UCI数据库常用来比较各种方法的分类效果,因此可以用其验证本算法对支持向量机作用后的分类效果[9][10]。文献[11]采用了UCI数据库中的German、Ionosphere和Sonar三种数据作为实验对象,为了便于与文献[11]中所用的几种方法进行对比,本文也采用这三种数据进行实验,并按照文献中所述的比例将各类数据分成相应的训练样本和测试样本。
在种群规模为30,交叉率为0.8,起始变异率为0.1的条件下使用支持向量机作为分类器(惩罚参数为13.7,径向基核函数参数为10.6)对所选数据进行分类,表1中显示了本文算法与文献[11]中几种算法在分类效果上的对比,表2给出了三种数据的最终选择结果。表1中共出现了四种方法:方法1:使用本文算法;方法2:使用NGA/PCA方法;方法3:使用PCA方法;方法4:使用简单遗传算法。
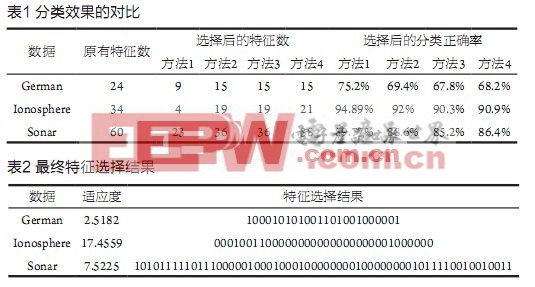
由于本文算法旨在用最少的特征个数最大化分类正确率,因此从表1中可以看出本文算法在特征选择个数和分类正确率上均比其他三种方法更具优势。由于NGA/PCA算法是针对简单遗传算法和主成分分析法的不足而做的改进,其性能优于简单遗传算法和主成分分析法,所以本文算法的分类效果优于NGA/PCA算法这一事实更能说明该算法可以较好地解决支持向量机的特征选择问题。
结语
通过与其他方法的比较,本文算法的分类效果得到了充分的验证,也说明了该算法具有极好的泛化能力以及在敏感度信息量地指导下遗传操作的有效性。
适应度函数的设计至关重要,它直接影响到最终结果的优劣以及算法的收敛性,所以在适应度函数的设计应考虑所解决问题的侧重点。
分类正确率的高低不仅取决于合理的特征选择,而且与支持向量机的参数优化有关。只有在合理的特征选择和参数优化的前提下,支持向量机分类器才能发挥出最佳的分类效果。
由于算法能够较好地解决支持向量机的特征选择问题,因此已被应用在基于支持向量机的数字电路板故障诊断当中,并取得了良好的效果。

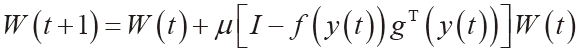




评论