基于叠加训练序列光OFDM系统帧同步算法FPGA实现
3.1 功率分配因子与BER性能
通过不同信噪比下的系统BER性能及不同功率分配因子下的算法同步正确率仿真综合得出最佳功率分配因子,仿真结果如图3,图4所示。本文引用地址:http://www.eepw.com.cn/article/153538.htm
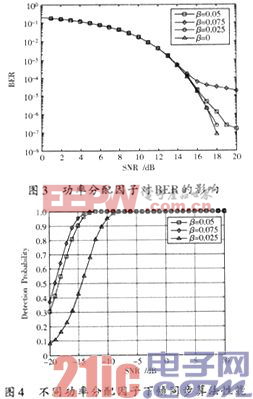
从图3,图4可以看出,当功率分配因子逐渐增大时,意味着叠加在数据OFDM符号上的能量越来越大,使得目标函数的能量值越大。但系统的BER性能变得越来越差,相反算法的同步性能变得越来越好。权衡两者性能,选择最佳功率分配因子β=0.05,后续将以此功率分配因子为基础进行仿真。需要说明的是,仿真系统BER性能的时候,将叠加训练序列作为干扰信息,没有进行信道估计,因此图3中不会出现极值现象。
3.2 同步性能仿真比较
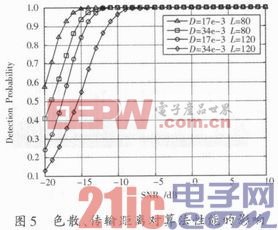
图5中给出了色散系数分别为17 ps/(nm·km)和34 ps/(nm·km)下不同传输距离的算法同步性能仿真。D表示色散系数,L表示传输距离。可以看出,相同色散下,传输距离越长,光能量损耗越大,使得算法同步性能变差;同时相同传输距离下,不同色散系数对算法的同步性能也将产生影响,色散系数越大,使得同步性能变差。由此可以判断在光OFDM系统中,光纤的色散和传输距离会影响算法的同步性能。
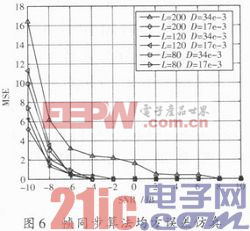
为了更加突出帧同步算法性能的优越性,图6将通过仿真验证算法的均方误差(Mean Square Error,MSE)性能。可以看出,算法随着信噪比的增大,趋近于稳定,收敛性较快。在信噪比大于-2 dB的情况下,算法性能稳定。
构造的训练序列具有良好的自相关性能,同时对于接收信号进行简单的移位截取镜像叠加处理,把长序列相关转换为短序列相关,降低了计算量,减少硬件资源的消耗。文献中采用长度为512的m序列,算法2采用了两次循环嵌套的累积求和方法,算法3利用求平均的方式,而本文采用长度为256的序列,将截取长度为512的接收信号进行镜像叠加处理,把长序列的乘积转化为短序列的乘积,降低了使用乘法器的次数,同时采用的训练序列比文献中的要短。因此,本文的同步算法在计算复杂度上比文献中的算法2和算法3更具优势。
4 帧同步算法的FPGA仿真实现
4.1 训练序列产生
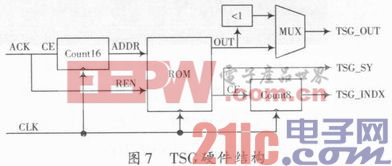
训练序列产生(Training Sequence Generator,TSG)模块的硬件实现结构如图7所示。TSG采用频率为20 MHz时钟进行基带处理。从微处理器送出的控制信号ACK用来启动TSG模块的工作。与IM/DDO-OFDM符号长度N(N=64)保持一致,ACK信号持续拉高1 025个时钟,一共持续完成64个周期的训练序列输出,每个周期内有16个时域样值。其中,TSG模块输出数据采用8位带符号的二进制表示,后8个周期TSG模块输出数据与前8个周期输出的数据具有镜像对称关系。


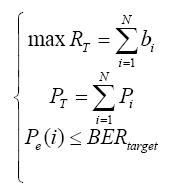




评论