JPEG2000核心算法的研究及DSP实现
 本文引用地址:http://www.eepw.com.cn/article/152456.htm
本文引用地址:http://www.eepw.com.cn/article/152456.htm图3 位平面编码三个通道系数编码数量变化示意图
通过对压缩性能研究发现,在压缩比较小时本文改进算法比标准算法的压缩性能约低0.4db左右,在压缩比较大时两者的压缩性能相一致,保留了JPEG2000优异的压缩性能;从编解码时间来看,在有损压缩编码执行时间上,本文所给出的改进算法比标准算法时间缩短8%到12%,解码时间缩短2%到5%,提高了编码效率,达到了改进的目的。
3 JPEG2000标准中改进算法的DSP实现
3.1 DSP硬件开发平台
本文使用评估板是北京闻亭公司的TDS642,板上的DSP芯片是TMX DM642,BGA548封装,内部工作时钟为600M,外部总线时钟为100M,计算能力高达4.8亿指令每秒。
该平台提供了丰富的外围接口。板上有两个复合视频(PAL/NTSC/SECAMS)输入和1个复合视频输出端口;立体声输入/出或单一麦克风输入端口;提供两个UART、以太网接口、子板接口、PC104接口和JTAG接口[6][7]。板上还提供了4M Bytes的Flash存储器,位于DM642的CE1地址空间,宽度为8bits,FPGA扩展了3根地址线,把Flash分成8页,Flash 的第0页的前半页存放用户的自启动程序,后半页存放FPGA程序,第1页尾用户存放数据空间,第2页至第8页用于存放用户程序。
3.2 核心算法的DSP实现
(1)算法总体框架。本文算法基于DM642EVM实现时主要分为两个大的模块(如图4),第一部分为DWT变换模块,它将输入图像数据变换为一系列的小波系数;第二部分为EBCOT算法模块,将量化后的的小波系数编码生成压缩码流。硬件开发平台结构框图如图5所示。

图4 算法框架图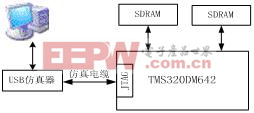
图5 算法硬件开发平台结构框图
(2)内存分配。对于图像数据的处理,往往涉及到大量的复杂的数据寻址计算,对于复杂的寻址计算,其耗费CPU的计算量可能比实际数据操作的计算量还大。所以要加快CPU对数据的访问速度,不但要求存储器本身的速度快,而且还需要一个合理的数据结构来简化CPU对地址的计算。另外,DM642对数据的访问技术,如Cache、EDMA和宽bit数据直接读写等,都是基于存储地址的连续性。基于以上考虑,本文在内存分配及定位时,依据以下大的原则:第一,在满足精度要求的情况下,使用较短的数据类型;第二、大的数据块,如原始图像、重构图像存储在片外SDRAM;第三、关键数据、小的数据块,比如运算时的系数、系统堆栈、三个通道扫描都需要频繁的访问数据区和上下文标志区等,存放到片内存储器;第四、对L2级配置足够的Cache以便CPU对数据的快速读写;第五、对于具有运算相关性的数据,应在内存中按序连续排放。当涉及到片内外数据块的搬移操作时,可由DM642的EDMA单元去完成,它可与CPU并行工作,不占用CPU的计算周期[8]。
(3)图像数据的读写。由于本文工作主要完成针对图像的压缩功能,不涉及图像采集,所以在图像数据的输入输出上做了适当的处理。考虑到CCS的Simulator完全支持C/C++语言,因此原始图像数据的输入采用C语言中的头文件形式,小波变换模块,EBCOT算法模块采用存放在PC机的数据文件形式。本文主要采用头文件和二进制数据文件的形式,将图像的非文件头部分的所有数据通过“fprintf(fp,“%3d,”,image_in [i][j])”语句写到.h文件中。
(4)DWT的实现。由于DM642为定点处理器,不适合于浮点运算,所以本文选择LeGall(5,3)整数滤波器完成JPEG2000中的小波变换。在进行小波变换时,首先定义两个与图像块大小相等的存储缓冲器,一个是图像片数据的输入缓存Buf,一个是用来临时存放图像片数据经小波变换后的结果缓存TempBuf。每经过一级小波变换,图像片数据都要先后两次经过integer(5,3)的低通和高通滤波。TempBuf中保存的高通滤波数据经integer(5,3)滤波器处理后,得到HL子带和HH子带的小波变换系数。最后将变换结果存放到输入缓存Buf中。若要进行下一级分解,只需对Buf中LL子带进行同样处理。









评论