基于LZW算法的数据无损压缩硬件实现
当前数据压缩技术分为有损压缩和无损压缩,算术编码、游程编码、霍夫曼和LZW压缩是传统的数据压缩方法,属于无损数据压缩;而基于小波变换的数据压缩和基于神经网络的编码方式是近年来新发展起来的现代数据压缩方法,属于有损数据压缩。本研究主要探讨一种基于LZW算法的数据无损压缩硬件实现。
本文引用地址:http://www.eepw.com.cn/article/150866.htmLZW压缩算法在压缩的过程中自适应建立一个字典,以后的数据同字典中的数据相匹配,匹配上则输出字典的索引。由于表示字典的索引所用的比特数远小于字符的比特数,从而达到压缩的效果。这个生成的字典不需要随着压缩的数据一同传输,而是能够根据压缩的数据在解压时重新动态生成一模一样的字典。
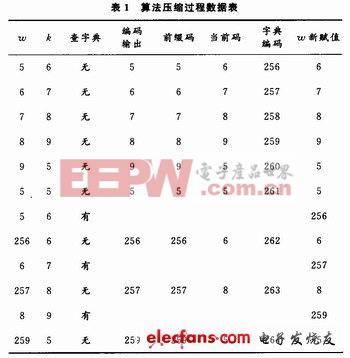
LZW编码原理如图1所示,在进行压缩时首先把字典中的前256(0~255)项初始为全部的256个8位字符,分别为十进制数0~255。当输入第一个字符时,总是在字典中可以找到,直到新的字符X不在字典词条中时,便将字符串IX加入到字典的第256项,以此类推。以字符串流5,6,7,8,9,5,5,6,6,7,8,9,5,…为例,表1给出了字典存储的物理结构和压缩过程中字典项的读写示意。压缩后编码输出为5,6,7,8,9,5,256,257,259,…。
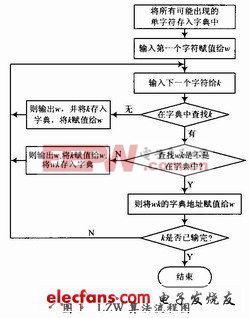
传统的LZW压缩算法采用8位数据输入,固定长度编码输出,随着字典内容的不断增多,输出编码的位数不断增加势必造成资源的浪费,也会损失压缩率。另外,由于字典的容量有限,随着压缩过程的进行,字典会被填满,若是简单的不再向字典中增加内容,那么后面的压缩率就会降低,而如果将字典全部清除重新建立字典,在字典建立初期压缩率也是很低的。针对以上不足,文献对LZW算法做以下改进:采用12位数据作为压缩输入,变长度的码字输出。
压缩字典最多可容纳16 384个码,共分为三部分,其中0~4 095为12位输出,4 096~8 191为13位,8 192~16 383为14位。每当输出长度变化时,同时输出一个变长标识,便于解码器解码。


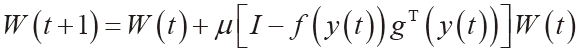










评论