一种基于密度的聚类的算法
2.2 改进的算法
DBSCAN算法在对类的划分时采用的方法是:比较此数据点到各类中心的距离,若小于某阈值,则属于此类。可见阈值的选择直接影响类的划分及类的数目。但是如图1所产生的聚类模块[3]所示,这种方法带来的问题就是:距离近的不一定属于同一类,在阈值半径内的不一定属于同一类。

针对此问题,本文提出一种改进的算法M-DBSCAN。首先实现在线聚类,可以动态调整聚类的数目;之后,通过将数据点到类的平均距离与类内平均距离以及新半径与原半径作比较进行双重判决,确定数据点是否可以加入此类中,以实时调整阈值半径,解决了类划分错误的问题。
改进后整个算法描述如下:
(1)积累一小段时间内的数据,得到相似度矩阵
(2)给定阈值dthr,找出邻域密度最大的数据点作为第一个初始类的中心c1,计算S中每行值大于dthr的个数,个数最多的行号即为第一个类的中心,将第一类中的数据点存放到矩阵S’(n×n+2)的第一行,每行中的第一个为类中心,计算类的平均半径r,同时计算此类的平均距离d2,放到最后两位。
(3)对尚未加入的数据点,计算某一个数据点到类c1中的所有点的平均距离d1,类的平均距离d2;
若d1d2,则判断加入此数据后类的半径是否变大;如果变小,将数据点加入此类,同时改变此类的平均半径;否则寻找下一个聚类,计算同上。
如果不能加入到任何一个已有聚类,则创建一个新的类,将其存入S’中。

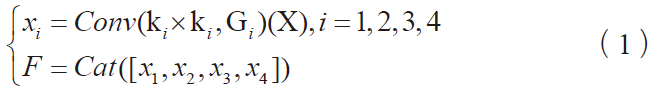








评论