TI 全新TMS320C66x 定点与浮点DSP内核成功挑战速度极限
图 2 所示的 TI 最新 C66x 内核具有同 C64x+ 内核相同的基本 A B 结构。请注意,.M 单元的 16 位乘法器已增至每个功能单元 16 个,从而实现内核原始计算能力提升 4 倍。C66x DSP 实现的突破性创新使得由 4 个乘法器组成的各群集可协同工作以实施单精度浮点乘法运算。
图 2 - TI 最新 C66x DSP 内核
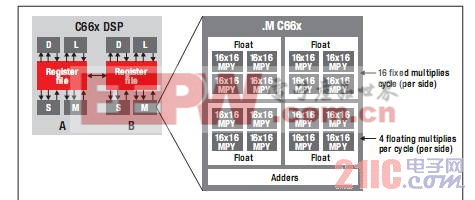
C66x DSP 内核可同时运行多达八项浮点乘法运算,加之高达 1.25 GHz 的时钟频率,使其当之无愧地成为市场上性能最高的浮点 DSP。将多个 C66x DSP 内核进行完美整合,即可创建出具有出众性能的多内核片上系统 (SoC) 设备。
浮点技术的成本为使定点与浮点组件都能同时实现最佳性能,TI 专为该款最新的 C66x 内核开发了全新的浮点与定点指令,所有这些都对实现高效率的无线信号处理至关重要。由于采用浮点符号会带来额外的计算复杂度,从而导致了定点与浮点处理器“分庭抗礼”的局面。在定点运算情况下,加法、乘法等基本操作简单易行,但在浮点运算情况下,这些基本操作需要做更多工作量。比如两个浮点数相乘的情形:
请注意,指数需要相加操作,尾数则需要相乘操作。然后,最终 (M1×M2) 值需调整成 23 位的表示形式,这可能需要对指数的值也作更改。使用浮点技术进行所有基本运算时将需要很多额外的操作。
浮点计算带来的额外复杂度恰好说明了众多算法仅采用定点表示数和定点运算的原因。嵌入式处理器能够更快地运行定点运算,并且在众多情况下,只需要定点算法即可。例如,C66x DSP 内核在每个周期内都能执行 16 项定点乘法运算或者是 4 项浮点乘法运算。为使定点和浮点组件都能同时实现最佳性能,TI 为该款最新的 C66x DSP 内核开发了定点与浮点运算指令,所有这些都对实现高效率的无线基站信号处理至关重要。浮点指令 FPi 包括:
1. 单精度复数乘法
2. 矢量乘法
3. 单精度矢量加减法
4. 单精度浮点-整数之间的矢量变换
5. 支持双精度浮点算术运算(加、减、乘、除及与整数间的转换)并且完全为管线式
最新定点指令可实现最佳的矢量信号处理 (VSPi),其中包括:
1. 复数矢量和矩阵乘法,诸如针对矢量的 DCMPY,以及针对矩阵乘法的CMATMPYR1
2. 实矢量乘法
3. 增强型点积计算
4. 矢量加减法
5. 矢量位移
6. 矢量比较
7. 矢量打包与拆包









评论