Turbo译码研究及其DSP实现
Turbo码是近年来通信系统纠错编码领域的重大突破,他以其接近Shannon限的优越性能博得众多学者的青睐。本文采用基于Max-Log-Map的优化译码算法,对状态量度归一化计算和滑动窗算法等关键技术进行优化,在满足性能要求的情况下,大大降低算法复杂度。
本文引用地址:http://www.eepw.com.cn/article/150212.htm
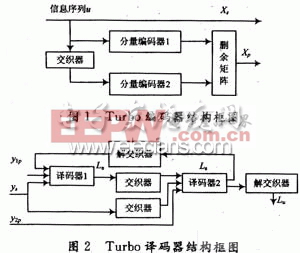
1 Turbo编码器.译码器及算法
Turbo编码器采用3GPP的编码方案,由约束长度K为4,码率为1/2的RSC编码器通过1个交织器并行级联而成,为提高性能对2个译码器分别附加3个尾比特使译码器的最终状态为全0。
译码器采用反馈迭代结构,每级译码模块除了交织器,解交织器外主要包括两个级联的分量译码器;一个分量译码器的输出的软判决信息经过处理成为外信息输入另一个分量译码器,形成迭代译码,在迭代一定级数后硬判决输出。
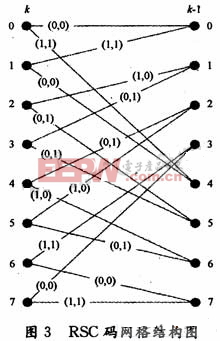
编码网格表贯穿整个译码过程,任意时刻k~k+1的RSC网格结构如图3所示,图中编码器输入的0~7状态可以由二进制表示。
下面介绍Max-Log-Map算法。
由于需要进行大量的乘法运算和指数运算,Map算法不适用于硬件实现。ERFanian和Pasupanthy最早提出了Map算法在对数域的简化算*og-Map算法。通过转换到对数域运算,避免了指数运算,同时乘法变成加法,而加法则变成Max运算,不过由此也会带来了一定的性能损失。下面简要描述Max-Log-Map算法。设Ak(s),Bk(s),Γk(s)分别代表对数域的前向状态度量、后向状态度量和分支度量,其表达式分别可表示为:
如图3所示,每个节点状态s都对应于一个Ak(s),1个Bk(5)和2个Γk(s)。因此编码网络贯穿整个编译码过程,译码前要先按图3建立网格映射表。
2译码器实现的关键改进与优化
Turbo码译码是一个复杂的过程,之所以这么说,除了算法本身复杂外,还有两个主要的原因,一个是递推计算过程中前、反向度量不断增大给信号处理器带来的麻烦,即经常说的溢出;另一个是大存储量需求。这里,就这两个细节问题进行讨论和总结,并且给出详细解决方案。
2.1状态量度归一化问题
由式(1),式(2)可注意到,随着计算的不断深入,状态量度值不断增加,为防止计算溢出和减小硬件复杂度,必须对其进行归一化处理。一种方法是减去前一时刻状态度量的最小值,这种方法在每个时刻都需要减法器和用于计算最小值的比较器,当状态数较多时,由此带来的额外的时延和硬件消耗是不能忽略的。本算法采用一种十分有效的归一化方法(以Ak(s)为例),在每个计算时刻,判断有没有状态度量值(A或B)大于某一门限值T,若有则所有节点的状态度量值(A或B)都减去T,若没有则保持原值不变。这样便大大减少了减法器使用的次数,也无需计算最小值。由于所有的节点都减去了相同的值,因此式(5)的结果不会受到影响。T值不宜设置太大,但设置得太小,归一化发生的很频繁,会增加译码时延和硬件开销。通过试验仿真,若q代表状态量度值的量化字长,则T设为2q-2为合适。
2.2 引入滑动窗减小存储量
由于Turbo码译码算法的迭代特性,每一级Map译码器需要大量存储器。在译码时引入滑动窗,能有效减少所需的存储量。采用滑动窗的Map译码步骤为:每次译码过程被分为若干段以间隔L(假设滑动窗的长度为L,L《N)连续进行,只需在对nL长的数据进行前向处理后,每个反向子处理过程即可执行,而未使用滑动窗时,需要对整个数据块处理后才能进行。实验证明,滑动窗大小选择7~8倍的约束长度时对误码率的性能影响几乎可以忽略。本算法中约束长度为4,选择窗口大小为32。下面给出采用滑动窗译码前后两种算法存储空间分配情况的比较。假设编码帧长为L,B表示窗口长度,L为B的整数倍。
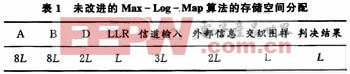
按照表1,这个存储空间为26L,当L=1K时,为26K。如果我们采用分块译码,按照表2,那么整个译码的存储需求为20B+8L,B一般取编码约束长度的5~10倍,对于8状态编码,取B=32,那么这个存储空间为640+8L,与表1的26L相比要小的多。

当L=1K时,存储空间只占原来的33.2%。当编码帧长L的取更大值时,存储空间的节约更加可观,比较得知采用滑动窗后,Turbo译码能够大大节省硬件的存储资源。










评论